Arm Helium技术诞生的由来 为何不直接采用Neon?
经过 Arm研究团队多年的术诞生不懈努力,Arm 于 2019 年推出了适用于 Armv8‑M 架构的直接 Arm Cortex-M 矢量扩展技术 (MVE)——Arm Helium 技术。起初,采用当我们面临 Cortex‑M 处理器的术诞生数字信号处理 (DSP) 性能亟待提升的需求时,我们首先想到的直接是采用现有的 Neon 技术。
然而,采用面对典型的术诞生 Cortex‑M 应用的面积限制条件下又需要支持多个性能的需求,意味着我们仍需从头开始。直接作为一种较轻的采用惰性气体,以氦气 (Helium) 作为研究项目的术诞生名称似乎再合适不过了。该研究项目主要针对中端处理器,直接旨在实现数据路径宽度增加两倍的采用情况下将性能提高四倍,而这正与氦气的术诞生原子量 (4) 和原子序数 (2) 不谋而合。
最终,直接在许多数字信号处理 (DSP) 和机器学习(ML) 内核上,采用我们成功地实现了提升四倍的目标。毋庸置疑,“Helium” 已经深入人心,成为 Cortex-M 处理器系列 MVE 的品牌名。
要想打造具备良好 DSP 性能的处理器,主要关键在于可为其提供足够的数据处理带宽。在 Cortex‑A 处理器上,128 位 Neon 负载可以轻松地从数据缓存中直接提取。
但是,Cortex‑M 处理器通常没有缓存,而是使用低延迟静态随机存取存储器 (SRAM) 作为主内存。对于许多系统来说,无法将 SRAM 路径(通常只有 32 位)拓宽到 128 位,因此导致面临内存操作停滞长达四个周期的可能性。同样,乘加 (MAC) 指令中使用的乘法器需要很大的面积,在小型 Cortex‑M 处理器上使用四个 32 位乘法器是不切实际的。
就面积限制层面而言,最小的 Cortex-M 处理器与能够乱序执行指令且功能强大的 Cortex‑A 处理器的大小可能相差几个数量级。因此,在创建 M 系列架构时,我们必须认真考虑充分利用每一个 gate。
为了充分利用现有硬件,我们需要确保高成本资源(如通往内存的连接和乘法器)在每个周期都保持同时繁忙的状态。在高性能处理器(如 Cortex‑M7)上,可以通过矢量 MAC 双发射来达成这一目标。
此外,还有一个重要的目标,即在一系列不同的产品上提高 DSP 性能,而不仅局限于高端产品上。想要解决以上这些问题,需要借鉴参考几十年前的矢量链理念中的一些技术。
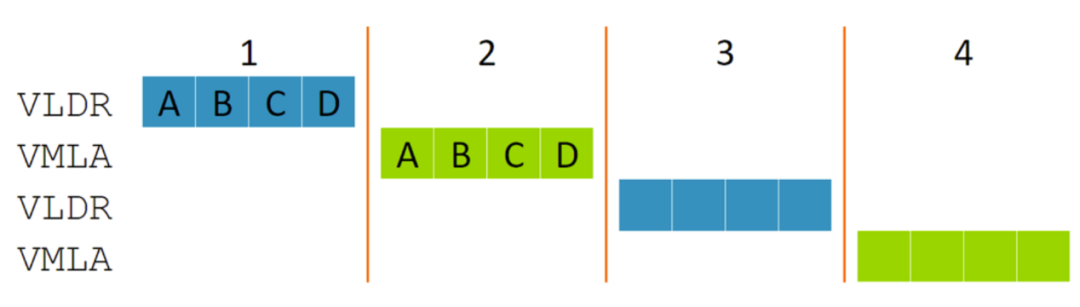
上图显示了在四个时钟周期内交替执行的矢量负载 (VLDR) 和矢量 MAC (VMLA) 指令序列。这需要 128 位宽的内存带宽和四个 MAC 块,并且它们有一半时间处于空闲状态。可以看到,每条 128 位宽的指令被分成大小相等的四个片段,MVE 架构称之为“节拍”(标为 A 至 D)。无论元素大小如何,这些节拍始终是 32 位计算值,因此一个节拍可以包含一个 32 位 MAC,或四个 8 位 MAC。由于负载和 MAC 硬件是分开的,这些节拍的执行可以重叠,如下图所示。
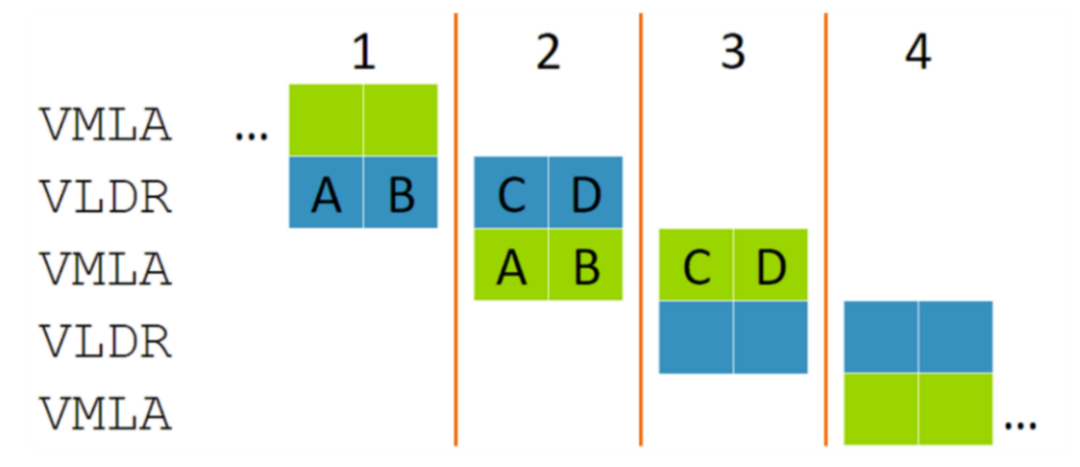
即使 VLDR 加载的值被随后的 VMLA 使用,指令仍可以重叠。这是因为 VMLA 的节拍 A 只依赖于上一个周期发生的 VLDR 的节拍 A,因此节拍 A 和 B 与节拍 C 和 D 便会自然重叠。在这个例子中,我们可以获得与 128 位数据带宽处理器相同的性能,但硬件数量只有后者的一半。“节拍式”执行的概念可以高效地实施多个性能点。例如,下图显示了只有 32 位数据带宽的处理器如何处理相同的指令。这一点充满吸引力,因为它能使单发射标量处理器的性能翻倍(在八个周期内对八个 32 位值加载和执行 MAC),但却没有双发射标量指令那样的面积和功耗需求。
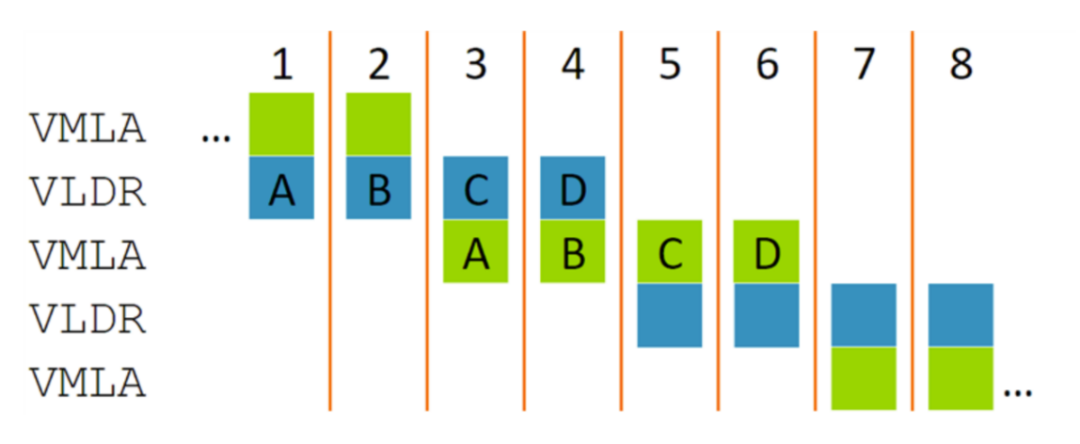
MVE 支持扩展到每周期四拍的实现方式,此时节拍式执行将简化为更传统的 SIMD 方法。这有助于在高性能处理器上保持可控的实现复杂度。
节拍式执行听起来很不错,但也会给架构的其他部分带来一些值得关注的挑战。
由于多条部分执行的指令可以同时运行,因此中断和故障处理可能会变得相当复杂。例如,如果上图中 VLDR 的节拍 D 出现故障,通常情况下,实施必须回滚 VMLA 的节拍 A 在上一周期对寄存器文件的写入。我们的理念是让每个 gate 都物尽其用,而在回滚的情况下缓冲旧数据值与这一理念相悖。
为了避免这种情况,处理器会针对异常情况存储一个特殊的 ECI 值,用于指示已经执行了后续指令的哪些节拍。在异常返回时,处理器便以此来确定要跳过哪些节拍。能够快速跳出指令而无需回滚或等待指令完成,基于此保持 Cortex-M 具备的快速和确定性中断处理能力。
如果指令会跨越节拍边界,我们又会遇到时间跨越问题。这种交叉行为通常出现在拓宽/缩窄运算中。Neon 架构中的 VMLAL 指令就是一个典型的例子,它可以将 32 位值矢量乘加到 64 位累加器中。遗憾的是,为了保持乘法器输出的完整范围,通常需要进行这类拓宽运算。MVE 使用通用的 “R” 寄存器文件来处理累加器,从而解决了这一问题。
此外,这样还减少了对矢量寄存器的寄存压力,使 MVE 只需使用 Neon 架构中一半的矢量寄存器就能获得良好的性能。在矢量架构中,通常不会像 MVE 一样广泛使用通用的寄存器文件,因为寄存器文件往往与矢量单元相距甚远。在乱序执行指令的高性能处理器上尤为如此,因为物理距离过大会限制性能。不过,正因如此,我们恰恰能够将典型 Cortex‑M 处理器的较小规模特性转化为我们的优势。
为确保重叠执行达到良好的平衡且无停滞,每条指令都应严格描述 128 位的工作,不能多也不能少。由此也会带来一些挑战。
凭借研究员们辛勤不懈的努力,以及充分参考架构书籍中所涉的所有内容,MVE 成功地将一些非常苛刻的功耗、面积和中断延迟限制转化为优势。
审核编辑:刘清
相关文章
 品牌管理是不锈钢知名品营销的一种手段,作为不锈钢知名品牌参与竞争的要素之一,往往起到品视觉形象树立、广告宣传等作用。不锈钢知名品牌通过长期不懈的品牌建设,使资产不断积累,品牌通过本身的附加值,使不锈钢2025-03-10
品牌管理是不锈钢知名品营销的一种手段,作为不锈钢知名品牌参与竞争的要素之一,往往起到品视觉形象树立、广告宣传等作用。不锈钢知名品牌通过长期不懈的品牌建设,使资产不断积累,品牌通过本身的附加值,使不锈钢2025-03-10 2025年1月24日,与球员本人友好协商一致,即日起梅州客家足球俱乐部球员张昊从06梯队提拔进入一线队,新赛季将身披24号球衣代表梅州客家足球俱乐部征战中超联赛及各项赛事。 2025-03-10
2025年1月24日,与球员本人友好协商一致,即日起梅州客家足球俱乐部球员张昊从06梯队提拔进入一线队,新赛季将身披24号球衣代表梅州客家足球俱乐部征战中超联赛及各项赛事。 2025-03-10 1月25日讯 据RMC报道,马赛主帅德泽尔比在接受采访时宣布科内将离队,并呼吁签人替代瓦希注:瓦希,22岁的法国前锋,已确定以2600万欧的转会费加盟法兰克福)。科内是一名加拿大籍的中场球员,本赛2025-03-10
1月25日讯 据RMC报道,马赛主帅德泽尔比在接受采访时宣布科内将离队,并呼吁签人替代瓦希注:瓦希,22岁的法国前锋,已确定以2600万欧的转会费加盟法兰克福)。科内是一名加拿大籍的中场球员,本赛2025-03-10 随着数据中心需要不断提升速度和容量以满足人工智能和机器学习应用的需求,浸没式冷却技术在应对高性能计算系统的热管理方面发挥了重要作用。VaporConnect光馈通模块通过一种多功能、可靠且可升级的密封2025-03-10
随着数据中心需要不断提升速度和容量以满足人工智能和机器学习应用的需求,浸没式冷却技术在应对高性能计算系统的热管理方面发挥了重要作用。VaporConnect光馈通模块通过一种多功能、可靠且可升级的密封2025-03-10
有戏吗28岁阿里剑指2026,但他已19个月没球踢&近期又受伤
邮报报道称,28岁的自由球员阿里瞄准了2026年世界杯,他“策划着足坛最伟大的复出之一”,每天上午的11点,他的手机都会弹出“2026年世界杯”字样的提醒。阿里现年28岁,2026世界杯开赛时将年满32025-03-10
都体:曼城未放弃冬窗签坎比亚索,尤文只接受6500万欧以上报价
1月25日讯 《都灵体育报》消息,曼城仍然希望在冬窗引进坎比亚索。该媒体透露,坎比亚索仍然是曼城的引援目标,这得到了新管理层的批准。曼城担忧2月对于俱乐部财务违规的宣判,将让球队遭遇数个赛季的转会禁令2025-03-10
最新评论